 容灾产品
容灾产品 备份产品
备份产品 大数据产品
大数据产品 云灾备产品
云灾备产品 统一数据管理平台
统一数据管理平台

最早提出“大数据”时代到来的是全球知名咨询公司麦肯锡。麦肯锡称:“数据,已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。人们对于海量数据的挖掘和运用,预示着新一波生产率增长和消费者盈余浪潮的到来。” “大数据”在物理学、生物学、环境生态学等领域以及军事、金融、通讯等行业存在已有时日,却因为近年来互联网和信息行业的发展而引起人们关注。
2009年甲型H1N1流感爆发,有评论家警告,可能会出现类似1918年西班牙流感般大规模流行,影响5亿人口并夺走数千万人性命。在甲型H1N1流感爆发前几周,互联网巨头谷歌公司在《自然》杂志上发表的一篇论文,引起了业内的广泛关注。文中解释了谷歌为什么能够准确预测流感的传播:通过观察人们在网上的搜索记录来完成这个预测,而这种方法以前一直被忽略。谷歌保存了多年来所有的搜索记录,而且每天都会接受来自全球超过30亿条的搜索指令。如此庞大的数据资源足以支撑和帮助谷歌完成预测。
大数据开启了一次重大的时代转型,人们不再认为数据是静止和陈旧的。在以前,一旦完成了收集数据的目的之后,数据就会被认为已经没有用处了。但在大数据时代,数据本身发生了变化:
- 数据更多,不是随机样本,而是全体数据。
- 数据更杂,不是精确性,而是混杂性。
- 数据更好,不求因果关系,但求相关联系。
每个人都可以获取大量数据信息,而在数据洪流席卷全球的大数据时代,人类存储信息量的增长速度比世界经济的增长速度快4倍。到了2020年,全世界所产生的数据规模将达到8年前的44倍,国际数据公司IDC给出了详细的数字:全球数据总量2020年将达到40ZB,2025年将达到175ZB。面对海量数据,迅猛发展的数据处理能力依然捉襟见肘,在入仓速度与分析速率相悖而生的大数据体系架构下,面临两大考验:传统数据管理要如何完成架构转型,怎样寻求入仓速度与分析速率平衡点。

图1:大数据应用
大数据分析的基础是大量可信数据,数据同步工具可以为大数据分析平台提供源自实际业务的持续传送的可信数据。大数据平台汇聚了源自不同数据源的数据,因此可以从多维度、多视角实现数据采集、整合、清理、治理、分析,从而实现数据决策、趋势分析和数据可视化展示等。
随着大数据技术的发展和应用,数据同步的需求和频率也在提高,在了解基于日志抽取分析的数据流实时同步技术之前,先看一看数据同步的分类及基础知识点:
离线同步和在线同步:离线同步是指生产库不对外提供服务,数据不会发生变化。在线同步要复杂得多,数据库会一直对应用层系统提供服务,同步工具需要在数据不断变化的情况下,将变化的数据同步到目的库。如增删、更新、插入及DDL操作等。
准实时同步、实时同步、非实时同步:准实时接近于两边数据库同时操作,但会有延时;实时同步是两边都是写操作;非实时一般强调数据库不对外提供服务时,再进行数据同步。
通过日志、时间戳、全表拷贝的技术同步:日志分析是通过分析源数据库日志,捕获源数据库中变化的数据,一般用于大型数据源,如Oracle;时间戳是在同步的源表里有时间戳字段,当数据变化时,时间戳记录变化的时间;全表拷贝是定时清空目的数据源,然后将源库数据全盘拷贝到目的数据源,实时性不高。
数据仓库技术ETL(Extract-Transform-Load的缩写):描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目标端的过程。ETL常用在数据仓库,但其对象并不限于数据仓库。ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据,ETL是商业智能(BI)项目重要的一个环节。
JSON(JavaScript Object Notation) 文件:一种轻量级的数据交换格式文件,易于人阅读和编写,也易于机器解析和生成。JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C、C++、C#、Java、JavaScript、Perl、Python等)。这些特性使JSON成为理想的数据交换语言。JSON是Kafka平台可识别的格式文件。
Kafka流处理平台:Kafka是一种分布式消息队列,用于发布和订阅消息,可作为中间件将数据汇聚到数据湖、大数据应用和实时流分析系统中。Kafka具大容量存储和快速读写两大特点。Kafka的数据处理速度快可以通过批处理和压缩记录有效地使用IO。对于数据库数据,Kafka具备两大功能:一是异构数据库的解耦,实现大数据量的数据缓冲;二是异构数据库的格式转化,实现异构数据库的数据传输。
数据同步工具抽取数据并做转换、加载是数据进一步聚合、分析的基础。数据同步技术的发展一方面会提高同步过程的可靠性、可视化,增强应对异常的能力;一方面也会和人工智能的发展相结合,以提供深层次数据处理和实现数据事件的智能化响应。
基于前沿的数据库数据同步分析技术,英方软件推出了一种专注于面向预写日志抽取分析的数据库同步技术,可以从主流的结构化数据库获取数据的源头保证数据的完整性、可靠性,进而实现数据的提取和复制,并实时将数据传输到Kafka等消息队列。
该技术充当了Kafka Producer的角色,从关系型数据库解析生产数据,以JSON格式实时向Kafka平台写入,提供适用于大数据环境的高性能、容错、易用和灵活的实时数据流平台,帮助客户扩展实时数据集成架构到大数据系统而不会影响生产系统的性能。
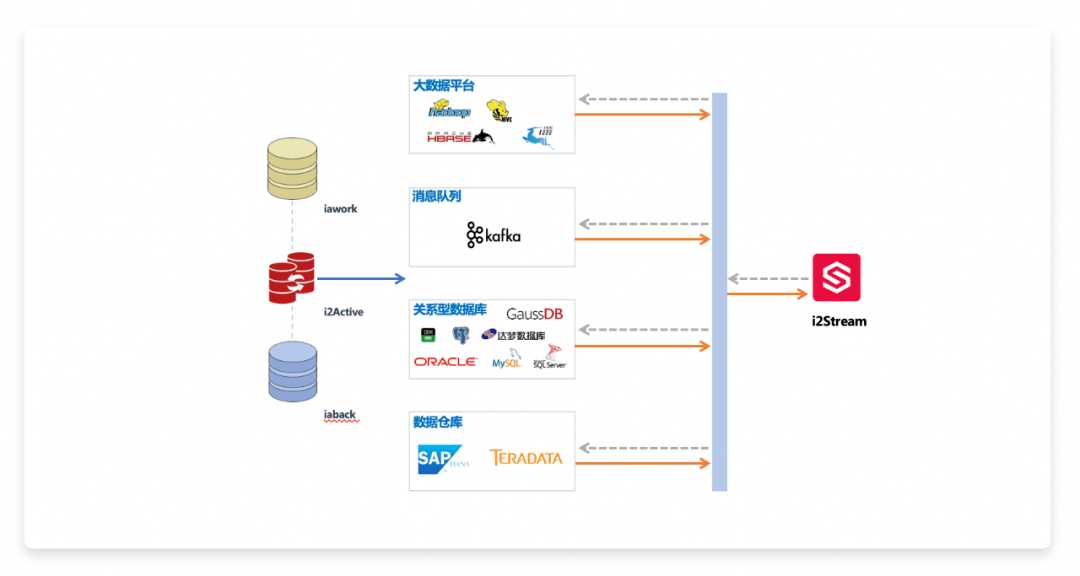
图2:i2Stream应用架构和场景
图3是关系型数据库Oracle到Kudu的数据抽取→转换→转载的过程,先通过数据库复制产品i2Active将源端数据库的结构化数据解析、提取后, 通过i2Stream进行对接、转换,并发送给消息队列,最终写入HDFS。在此基础上将数据同步到Kudu/HBase等数据仓库。
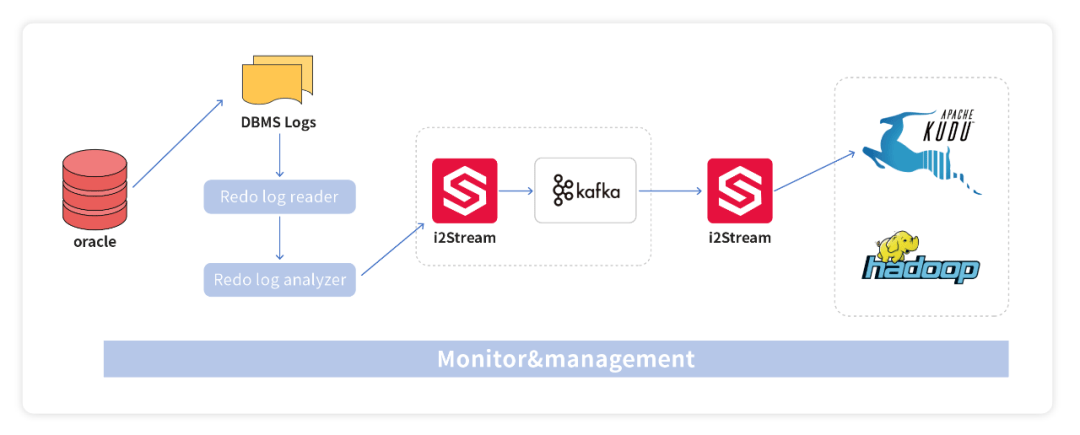
图3:数据从Oracle到Kudu的过程
基于该技术研发的管理软件i2Stream,主要功能包括:
- 支持结构化、异构数据源全量和实时增量快速加载到各类Hadoop(hdfs、Hive、HBase、Kudu)、Kafka、关系型数据库等目标库;
- 支持无侵入实时增量数据获取功能。功能支持的源端数据库包括Oracle(RAC)、SQLServer、MySQL、MariaDB、PostgreSQL、GaussDB、DB2等;
- 目标库支持关系型数据和Hadoop(hdfs、Hive、HBase、Kudu)、Kafka等多种大数据存储数据库;
- 支持表级、实例级的数据过滤和转换;
- 支持源数据库一对多分发到不同的目标库中,支持源库多对一汇聚到同一个目标库;
- 采用多线程流处理技术,数据转发性能高,秒级延时;
- 支持近实时大数据入仓(Hive),Hive的批量装载速度达到近万条;
- 采用B/S图形界面配置,简单易用。
相比其他数据流复制技术产品,i2Stream的优势在于可以提供较高的数据同步性能、图形化管理界面、可为客户提供系统监控API,客户可以自行整合监控数据到统一的管理平台。可以为客户提供数据验证手段,如同步后数据的比对、修复。可以为客户提供定制开发满足用户的特定需求等。
云和大数据时代,除了数据超多之外,还面临着系统超复杂(Gartner:2020年全球企业超过6成将实施双模IT,75%企业将应用基于容器的云原生架构)和环境超异构(RightScale:84%为多云环境,其中58%为混合云环境)的挑战,传统的大数据复制技术正在经历架构变化带来的转型阵痛,英方新的大数据复制技术在以往的经验上,适应了两大应用场景:
- 异构数据库数据的实时流通、交互,帮助用户完成核心数据的迁移、同步。
- 帮助证券、银行、支付平台实现大数据从数据库传输到大数据平台,再根据业务需要,转换成各类报表数据,为各类商业智能(BI)项目服务。
图4:大数据应用于金融系统
大数据技术正在发生深刻的变化,任何IT基础架构的变化和创新,都会引发新一轮的技术竞赛,在日益变化的客户场景中,没有最好的技术,只有合适的选择,用户因此需要根据自身的技术喜好和业务需求,做出正确的决策。

 沪公网安备 31010102007307号
沪公网安备 31010102007307号