 容灾产品
容灾产品 备份产品
备份产品 大数据产品
大数据产品 云灾备产品
云灾备产品 统一数据管理平台
统一数据管理平台数据序列化有很多应用,比如数据传输过程中,它可以确保两端数据库的数据要一致,比对不能出现差异。
数据序列化,关键词是序列化,它是将一个对象的状态(各个属性量)保存起来,然后在需要时释放。
序列化分为两大部分:序列化和反序列化。序列化是这个过程的第一部分,将数据分解成字节流(I/O),以便存储在文件中或在网络上传输。反序列化就是打开字节流并重构对象。对象序列化不仅要将基本数据类型转换成字节表示,有时还要恢复数据(恢复数据要求有恢复数据的对象实例)。
序列化的特点很明显,如果某个类能够被序列化,其子类也可以被序列化。声明为static和transient类型的成员数据不能被序列化。因为static代表类的状态,transient代表对象的临时数据。
在灾备领域,很多数据从生产端传输到灾备端时,会因为各种原因出现主备两端的数据不一致,导致用户的数据(库)迁移出现问题,造成更大的麻烦。
为此,英方股份通过多年的研发投入,成功研发出了特有的数据序列化传输技术(Data Order Transfer),严格保证生产系统和灾备中心数据的一致性和完整性。
在这个原理解释中,可以通过I/O层进行解释:
我们这样理解,文件系统的I/O操作通常是要求序列化的,因此这些操作日志也必须保持它原有的操作次序,尤其针对特殊类型的数据文件,如数据库文件等,要求对数据的截获、传输、存储进行严格的按源序处理,否则将导致灾备后的数据库不可用,英方的研发人员采用独有的DOT(Data Order Transfer)技术,严格保证数据各个环节的按序传输和处理,从而保证数据的一致性。
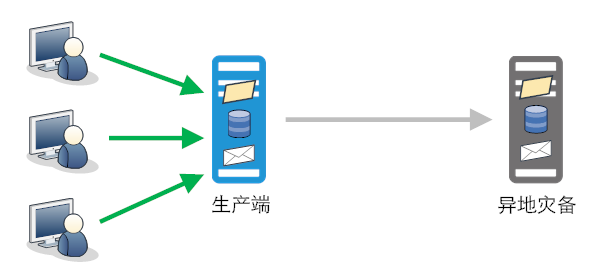
基础的灾备模型
这些截获模块在I/O操作被截获时的次序是序列化的,在内核态的截获模块向用户在拷贝过程中或在网络传输的过程中,由于拷贝的机制和线程调度的原因有可能导致这种次序被打乱,这种次序被打乱会破坏数据的一致性。源端工作机为保证I/O操作被截获时的次序真实正确地提供给灾备机,就需要在I/O操作被截获时为每个操作日志进行序列化排序,灾备机收到I/O操作日志后对个别乱序通过日志记录中的数字序号重新将I/O操作序列化,在和源端序列严格一致后再提交到灾备端写入。
这个如何理解英方数据序列化技术的优势呢,简单地说,传统的备份技术由于未能保存序列化的操作日志,在恢复数据粒度上取决于定期备份的精度,英方的恢复精度达到了系统每次I/O操作的级别,远远高于传统容灾备份技术。

 沪公网安备 31010102007307号
沪公网安备 31010102007307号