 容灾产品
容灾产品 备份产品
备份产品 大数据产品
大数据产品 云灾备产品
云灾备产品 统一数据管理平台
统一数据管理平台

又双叒叕-关键时刻掉链子
昨日,大批亚马逊卖家遭遇惊吓,店铺订单状况始终停留在8小时前,本以为黑五之前会爆单,谁料惨遭“0 单”。
据买家反馈,此次惊魂一场,原来是亚马逊系统故障的问题,而造成此次系统故障的原因就是亚马逊云服务 AWS 崩了。
美国当地时间周三下午 AWS 发出通知称:“北弗吉尼亚(US-EAST-1)区域的 Kinesis Data Streams API 受到影响,我们会继续努力,希望服务早一点恢复。Kinesis及几项受影响的服务错误率将会继续减少,不过全面恢复最多还需几个小时。”
 △AWS 通知
△AWS 通知
AWS 崩了已经不是一次两次了,据统计,十年来 AWS 已发生大型故障十多次,有网友总结了 AWS 历年故障:
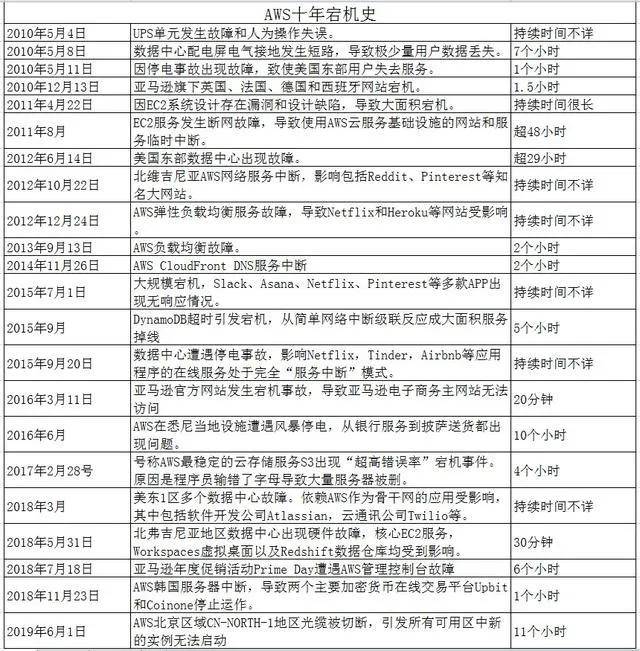 △图源自网络
△图源自网络
多次宕机事件发生,故障持续时间短则几十分钟,长则几十小时,甚至有的无法估量, AWS 的业务规模遍及全球,服务中断会造成多大损失,想一想就觉得窒息。
虽然 AWS 称,这些问题只影响其 23 个 AWS 地区中的一个。但此次事故的严重性已经到了数量众多的互联网服务瘫痪的地步。当日下午 5 点 25 分,AWS 在仪表板的最近更新中重申了完全恢复可能还需要几个小时。
企业上云是把双刃剑
在云计算、大数据快速发展的背景下,越来越多的企业选择公有云,实现计算、存储、网络等基础设施资源的统一管理和监控,极大降低了企业的运营成本。
AWS 作为全球最大的基础设施云提供商,2019 年以 32.3% 的市场占比,位居全球云市场榜首。此次宕机事件波及大量知名用户,包括 Adobe、Airbnb、Github、纳斯达克、Netflix、Slack、通用电气、Quora 等知名科技公司均被殃及。

此次 AWS 宕机事件再次昭示:云服务是把“双刃剑”,一方面为众多企业的业务快速部署带来了便利;另一方面,云平台发生故障时,云租户业务中断带来的损失又不可控,整不好会危机企业的经营。为此,租户在各类云平台必须建立起自己的信息安全保障体系,避免将鸡蛋放在一个篮子。
云平台高可用大势所趋
如何提高云平台架构下的抗风险能力,首先是安全防范意识的转变,即把数据灾难当作“常规事件”而非“异常”进行处理;其次,要强化数据和系统在云平台的高可用建设,通过具体可靠的技术工具、方案,保障企业用户数据的安全性和业务连续性。
为此,不管是云计算厂商还是上云企业,高可用都成为业务架构中必须考虑的因素之一。
高可用(High Availability)通常是指通过设计减少系统不能提供服务的时间。如果一台系统能够不间断的提供服务,那么这台系统的可用性为 100% 。通常情况下,为了保障关键系统的高可用,IT 运维管理员会进行系统架构的冗余设计,例如本地的双柜双活策略、异地一对一或多对一高可用策略等。
在异地高可用建设中,通过 HA 产品实时监控生产中心的运行情况,一旦判断生产中心出现业务不可达(如服务异常停止、网络异常、硬件故障、生产系统宕机维护),立即将业务切换到备端进行接管,从而保障业务连续性,实现系统的高可用。
在云平台的高可用建设类别中,可以分为两个层面:
一是云服务供应商在云数据中心可用区内设计高可用架构,或是在跨区域的可用区内实现系统高可用,但通常成本较高,并且如果是逻辑错误,可能还会无法避免系统故障或数据丢失;
二是有实力的企业可以选择“云到本地”的高可用,即公有云平台上的关键系统和数据,实时灾备到本地机房,避免云平台宕机时造成的业务中断和数据丢失。

对于金融级或其他大型机构,也可以通过自身的团队和资源,搭建机构私有云,实现公有云、私有云和传统基础设施的混合应用,即打造高性价比、高安全性、高可用的混合云架构和混合云灾备安全架构,符合行业的监管要求。
如此一来,对于使用了类似 AWS 公有云的机构来说,即使云平台出现大面积的宕机,也可以通过云到本地、混合云等高可用进行业务的快速恢复。
云平台宕机时时有,做好自身系统高可用的架构建设,任何时候都不晚。

 沪公网安备 31010102007307号
沪公网安备 31010102007307号